Aprenda como executar o Apache Kafka no Kubernetes sem o Zookeeper, usando o protocolo de consenso Apache Kafka Raft (KRaft).
Antes de entrarmos na parte técnica, permita-me dar a você algum contexto sobre por que e como o KRaft surgiu.
Por que Kafka sem o ZooKeeper?
O Apache ZooKeeper tem sido uma parte integral do Kafka para coordenação distribuída e eleição de liderança. Embora tenha cumprido seu propósito com eficácia, gerenciar um conjunto do ZooKeeper ao lado do Kafka adicionou complexidade à implantação.
Desde a introdução do KIP-500, agora é possível executar o Kafka sem o ZooKeeper, simplificando a configuração e a manutenção. Assim, o modo KRaft utiliza um novo serviço de controlador de quórum no Kafka, que substitui o controlador anterior, e é uma variante baseada em eventos do protocolo de consenso Raft.
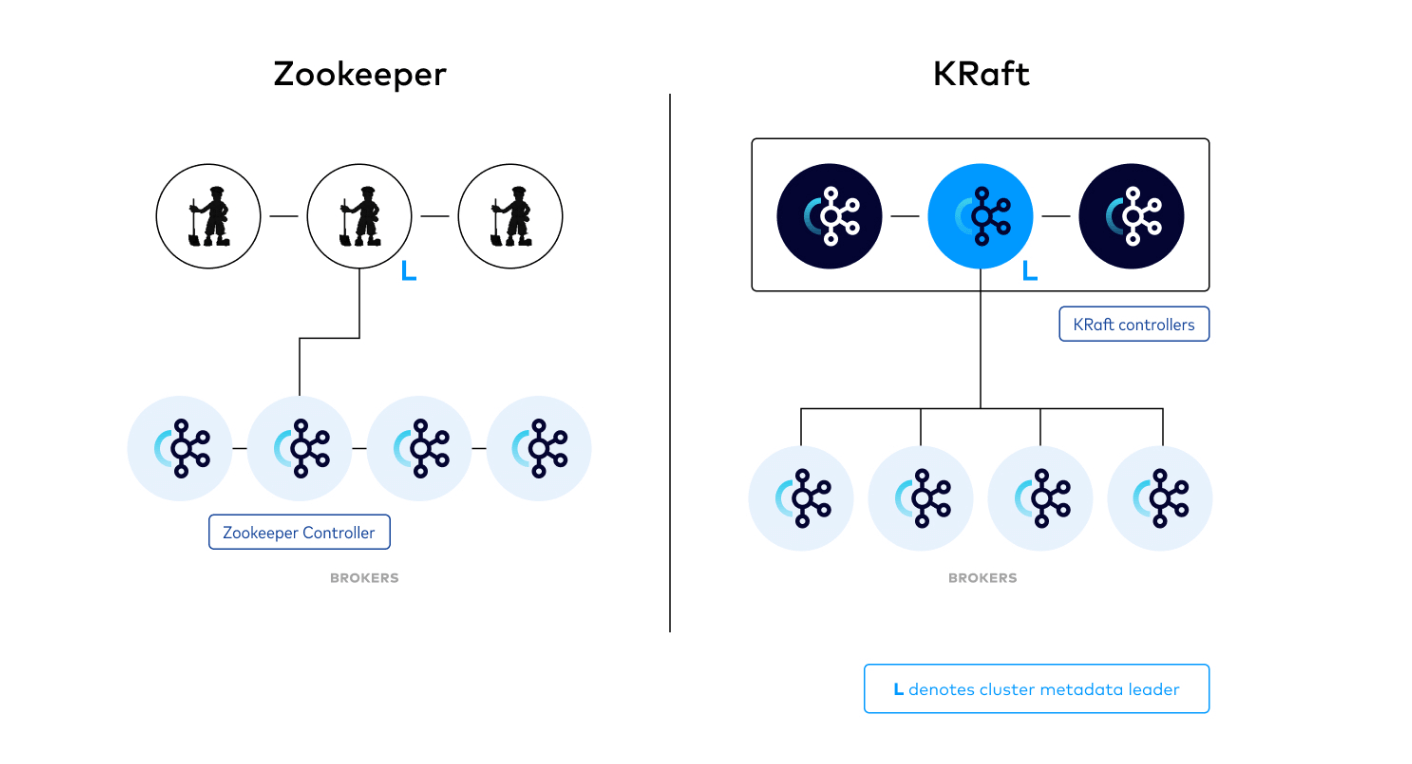
Zookeeper x Kraft – feito por: https://developer.confluent.io/learn/kraft/
Pré-requisitos
A fim de acompanhar este tutorial, é necessário ter um entendimento básico de Apache Kafka, Kubernetes e Minikube.
Os seguintes passos foram inicialmente realizados em um MacBook Pro com 32 GB de memória, executando o MacOSVentura v13.4.
Certifique-se de ter as seguintes aplicações instaladas:
-
Docker v23.0.5
- Minikube v1.29.0 (executando o K8s v1.26.1 internamente)
É possível que os passos abaixo funcionem com diferentes versões das ferramentas mencionadas acima, mas, se você encontrar problemas inesperados, é recomendável garantir que tenha as versões idênticas. O Minikube foi escolhido para este exercício devido ao seu foco no desenvolvimento local.
Componentes da Implantação
A implantação que criaremos terá os seguintes componentes:
- Namespace: kafka. Este é o namespace no qual todos os componentes serão abrangidos.
- Service Account: kafka. Contas de serviço (Service Accounts) são usadas para controlar permissões e acesso a recursos dentro do cluster.
- Headless Service: kafka-headless. Ele expõe as portas 9092 (para clientes do Kafka) e 29093 (para o Controlador do Kafka).
- StatefulSet: kafka. Ele gerencia os pods do Kafka e garante que eles tenham nomes de host e armazenamento estáveis.
O código-fonte para esta implantação pode ser encontrado neste repositório GitHub.
Criando a Implantaçāo
Para implantar o Apache Kafka no Kubernetes sem Zookeeper, primeiramente, clone o repositório a seguir:
git clone https://github.com/rafaelmnatali/kafka-k8s.git
Em seguida, implemente o Kafka usando os seguintes comandos:
kubectl apply -f 00-namespace.yaml kubectl apply -f 01-kafka-local.yaml
Verifique a comunicação entre os brokers
A principio, deve haver três nós (brokers) Kafka em execução. A resolução de nomes para o headless Service e os três pods dentro do StatefulSet é configurada automaticamente pelo Kubernetes conforme os Pods sāo criados, permitindo a comunicação entre os brokers. Consulte a documentação relacionada para obter mais detalhes sobre esse recurso.
Você pode verificar os logs do primeiro pod com o seguinte comando:
kubectl logs kafka-0
A resoluçāo de nomes para os três pods pode demorar mais tempo do que o pod a iniciar, entāo, você pode ver erros UnknownHostException nos logs durante a inicializaçāo:
WARN [RaftManager nodeId=2] Error connecting to node kafka-1.kafka-headless.kafka.svc.cluster.local:29093 (id: 1 rack: null) (org.apache.kafka.clients.NetworkClient) java.net.UnknownHostException: kafka-1.kafka-headless.kafka.svc.cluster.local ...
Eventualmente, cada pod irá resolver os nomes e iniciar com uma mensagem afirmando que o broker foi unfenced:
INFO [Controller 0] Unfenced broker: UnfenceBrokerRecord(id=1, epoch=176) (org.apache.kafka.controller.ClusterControlManager)
Criar um tópico e testar a tolerância a falhas
Como vimos anteriormente, o Kafka StatefulSet está em execução com sucesso. Com o propósito de validar o Kafka, podemos criar um tópico, verificar a replicação deste tópico e depois ver como o sistema se recupera quando um pod é excluído.
Abra um terminal e entre no pod kafka-0:
kubectl exec -it kafka-0 -- bash
Crie um tópico chamado test com três partições e um fator de replicaçāo de 3.
kafka-topics --create --topic test --partitions 3 --replication-factor 3 --bootstrap-server kafka-0.kafka-headless.kafka.svc.cluster.local:9092
Verifique as partições do tópico estāo replicadas no três brokers:
kafka-topics --describe --topic test --bootstrap-server kafka-0.kafka-headless.kafka.svc.cluster.local:9092
A saída do comando anterior deve ser similar a esta:
Topic: test TopicId: WmMXgsr2RcyZU9ohfoTUWQ PartitionCount: 3 ReplicationFactor: 3 Configs: Topic: test Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2 Topic: test Partition: 1 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0 Topic: test Partition: 2 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Podemos ver que existem três réplicas sincronizadas (Isr).
Agora vamos simular a queda de um dos brokers. Abrar um novo terminal e entre o seguinte comando:
kubectl scale sts kafka --replicas 2
No terminal com o pod kafka-0 terminal, verifique que a replicaçāo do tópico está somente em dois brokers:
kafka-topics --describe --topic test --bootstrap-server kafka-0.kafka-headless.kafka.svc.cluster.local:9092 Topic: test TopicId: WmMXgsr2RcyZU9ohfoTUWQ PartitionCount: 3 ReplicationFactor: 3 Configs: Topic: test Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1 Topic: test Partition: 1 Leader: 1 Replicas: 1,2,0 Isr: 0,1 Topic: test Partition: 2 Leader: 0 Replicas: 2,0,1 Isr: 0,1
Podemos ver que existem duas réplicas sincronizadas (brokers 0 and 1).
Resumo
Em resumo, este tutorial mostrou como executar o Kafka no modo KRaft em um cluster Kubernetes. Tanto o Kafka quanto o Kubernetes são tecnologias populares, e este tutorial, espero, tenha proporcionado uma visão de como é cada vez mais fácil usar essas duas ferramentas juntas.


