A comunicação dentro de uma rede já existente ou com outra adjacente pode ser viabilizada com tecnologias que possibilitam a conexão de um nó diretamente a outro ou a comunicação de um nó com algum dispositivo da rede vizinha. A construção de uma rede global, no entanto, demanda uma maneira de interconectar diferentes tipos de redes e enlaces (links).
Dispositivos que interconectam enlaces de um mesmo tipo são conhecidos como switches. O trabalho principal de um switch é pegar pacotes que chegam em uma entrada e encaminhá-los (switch) para a saída correta de forma que eles alcancem o destino apropriado. Diante da grande variedade de tipos de redes existentes, a construção de uma rede global também precisa oferecer uma maneira de se interconectar diferentes enlaces e redes, ou seja, uma rede global precisa ser capaz de lidar com a heterogeneidade de tecnologias. Segundo Peterson e Davie, dispositivos que executam esse tipo de tarefa eram originalmente chamados de gatways, mas atualmente são mais conhecidos como roteadores.
Existem vários modos de um switch determinar o encaminhamento correto de um pacote, os quais podem ser classificados em duas abordagens: sem conexão ou datagrama e orientada a conexão ou circuito virtal.

Em um circuito virtual, o caminho entre o nó de origem e o de destino precisa ser estabelecido antes de que qualquer pacote seja enviado. De acordo com Tanenbaum e Wetherall, a conexão é chamada de circuito virtual em analogia aos circuitos físicos criados para o sistema de telefonia. Na RFC 1594, por outro lado, datagrama é definido como uma entidade independente e auto-contida de dados que carrega informações suficientes para que seu roteamento possa acontecer desde um computador de origem até um de destino sem depender de trocas prévias de informações entre os dois computadores nem da rede de transporte. O quadro a seguir apresenta um comparativo das principais diferenças entre circuitos virtuais e redes de datagramas. A tabela a seguir, adaptada do site FACE Prep , apresenta um comparativo das principais diferenças entre circuitos virtuais e redes de datagramas.
| Circuitos Virtuais | Redes de Datagramas |
|
Os circuitos virtuais são orientados à conexão, o que significa que há uma reserva de recursos, como buffers, largura de banda, etc. durante o tempo em que o circuito recém-configurado será usado por uma sessão de transferência de dados. |
É serviço sem conexão. Não há necessidade de reserva de recursos, pois não há caminho dedicado para uma sessão de conexão. |
|
Uma rede de circuito virtual usa um caminho fixo para uma sessão específica, após a qual interrompe a conexão e outro caminho deve ser configurado para a próxima sessão. |
Uma rede baseada em datagrama é uma rede comutada por pacote. Não há caminho fixo para a transmissão de dados. |
|
Todos os pacotes seguem o mesmo caminho e, portanto, um cabeçalho global é necessário apenas para o primeiro pacote de conexão e outros pacotes não o exigirão. |
Cada pacote é livre para escolher qualquer caminho e, portanto, todos os pacotes devem ser associados a um cabeçalho que contém informações sobre a origem e os dados da camada superior. |
|
Os pacotes chegam ao destino em ordem, pois os dados seguem o mesmo caminho. |
Pacotes de dados chegam ao destino em ordem aleatória, o que significa que eles não precisam chegar na ordem em que foram enviados. |
|
Os circuitos virtuais são altamente confiáveis. |
As redes de datagramas não são tão confiáveis quanto os circuitos virtuais. |
|
A implementação de circuitos virtuais é dispendiosa, pois cada vez que uma nova conexão precisa ser configurada, deve haver a reserva de recursos e manipulação de informações extras nos roteadores. |
É sempre mais fácil e econômico implementar redes de datagramas, pois não há necessidade de reserva de recursos e criação de um caminho dedicado toda vez que uma aplicação precisa se comunicar. |
A ideia básica de uma rede de datagramas é que todo pacote deve conter informação suficiente para possibilitar que um switch decida qual destino deve ser dado a ele. Em outras palavras, todo pacote contém o endereço completo de destino. Logo, na transmissão de datagramas, cada pacote é tratado como uma entidade separada e contém um cabeçalho com as informações completas sobre o destinatário pretendido. Os nós intermediários examinam o cabeçalho de um pacote e selecionam um link apropriado para um nó intermediário mais próximo do destino. Nesse sistema, os pacotes não seguem uma rota pré-estabelecida e os nós intermediários (geralmente roteadores) não exigem conhecimento prévio das rotas que serão usadas. Uma rede de datagramas funciona de forma análoga ao envio de uma mensagem através de uma série de cartões postais pelo correio. Cada cartão é enviado independentemente para o destino final (usando o serviço de correios). Para receber a mensagem inteira, o destinatário deve coletar todos os cartões postais e ordená-los na ordem original. Nem todos os cartões postais precisam ser entregues pelos correios e nem todos levam o mesmo período de tempo para chegar.
Em uma rede de datagramas, também conhecidas como “redes de melhor esforço”, a entrega não é garantida (embora geralmente sejam enviadas com segurança). Se melhorias no serviço de entrega forem necessárias, como a implementação de entrega confiável por exemplo, estas devem ser fornecidas pelos sistemas finais (ou seja, computadores do usuário) usando algum software adicional. A rede de datagramas mais comum é a Internet que usa o protocolo de rede IP (Internet Protocol). Aplicações que não exigem mais do que um serviço de melhor esforço podem ser suportados pelo uso direto de pacotes em uma rede de datagramas usando o protocolo de transporte UDP (User Datagram Protocol). Aplicações deste tipo incluem serviços de vídeo pela Internet, comunicação por voz, mensagens notificando um usuário de que recebeu novos emails, etc. A maioria das aplicações na Internet precisa de funções adicionais para fornecer comunicação confiável (como erros de fim-a-fim e controle de sequência). Alguns exemplos incluem o envio de e-mails, navegação em uma página na Internet ou o envio de um arquivo usando o protocolo de transferência de arquivos FTP (File Transfer Protocol). Essa confiabilidade garante que todos os dados sejam recebidos na ordem correta, sem duplicação ou perdas. Ela é fornecida por camadas adicionais de algoritmos de software implementados nos sistemas finais. Como citado pelo Electronics Research Group, um exemplo comum é o protocolo TCP – Transmission Control Protocol.
Uma rede de “melhor esforço”, em parte significa que, se algo der errado e o pacote for perdido, corrompido, entregue incorretamente ou de alguma forma não atingir o destino pretendido, a rede não fará nada – ela fez o seu melhor, e isso é tudo o que ela tem que fazer. Não faz nenhuma tentativa de se recuperar da falha. Às vezes, isso é chamado de serviço não confiável.
A Figura a seguir (adaptada de Peterson e Davie) apresenta um exemplo de rede de datagramas na qual os hosts tem os endereços A, B, C e assim por diante. Para decidir como encaminhar um pacote, um switch precisa consultar uma tabela de encaminhamento (também chamada de tabela de roteamento). Nesta figura, um exemplo de tabela de encaminhamento é apresentado para o switch 2. A construção deste tipo de tabela é uma tarefa simples quando o mapa completo de uma rede simples está disponível, tal como descrito nesta figura. No entanto, à medida que as redes se tornam maiores e mais complexas, a montagem manual destas tabelas tende a se tornar inviável.

Cabeçalho do Protocolo IPv4
O protocolo IP é tido como a ferramenta chave usada atualmente para a construção de redes escaláveis e heterogêneas. Na sua versão 4, um datagrama IP é composto de duas partes – um cabeçalho e um corpo onde os dados são transportados. O formato do cabeçalho é apresentado na figura abaixo (Fonte: TechTudo). Os bits são transmitidos da esquerda para direita e de cima para baixo, com o bit de mais alta ordem do campo versão sendo enviado primeiro. Observando cada campo no cabeçalho IP, é possível notar que o modelo “simples” da entrega de datagramas de melhor esforço ainda possui alguns recursos significativamente úteis. O campo Versão (4 bits), por exemplo especifica a versão do IP. A versão atual é a 4 e às vezes é chamada de IPv4. Vale ressaltar que colocar esse campo logo no início do datagrama facilita a redefinição de todo restante do formato do pacote nas versões subseqüentes; nestes casos, o software responsável pelo processamento do cabeçalho inicia examinando a versão e, a partir daí, é capaz de selecionar o caminho a ser seguido para processar o restante do pacote de acordo com o formato apropriado.
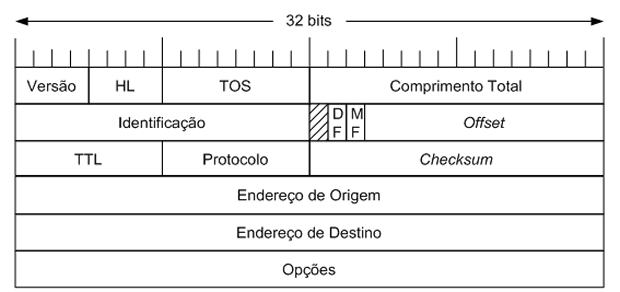
Os próximos 16 bits do cabeçalho contêm o comprimento total do datagrama, incluindo o cabeçalho. Ao contrário do campo HL, o campo Comprimento Total conta bytes em vez de palavras. Assim, o tamanho máximo de um datagrama IP é 65.535 bytes. A rede física na qual o IP está sendo executado, no entanto, pode não suportar pacotes tão longos. Por esse motivo, o IP suporta um processo de fragmentação e remontagem e a segunda palavra do cabeçalho contém informações sobre fragmentação. O campo Identificação (16 bits) é necessário para permitir que o host de destino determine a qual pacote pertence um fragmento recém-chegado. Todos os fragmentos de um pacote contém o mesmo valor de identificação. Em seguida, aparece um campo não utilizado, o que é surpreendente, tendo em vista os campos no cabeçalho IP serem extremamente escassos. Este bit é reservado é deve ter o valor 0. Na sequência, surgem dois campos de 1 bit relacionados à fragmentação do datagrama. DF significa Don’t Fragment e quando tem o valor 1, isso indica que os roteadores não devem fragmentar o pacote; caso contrário (valor igual a 0), ele pode ser fragmentado. Outro campo contendo um bit de controle é o MF (More Fragments), cujo objetivo é dar apoio aos hosts incapazes de juntar as peças novamente. Se o valor deste campo for 0, isso indica que o datagrama corresponde ao último fragmento, caso contrário (valor igual a 1), mais fragmentos ainda serão recebidos.
O campo Offset – ou deslocamento (13 bits) – do fragmento informa aonde no pacote atual esse fragmento se encaixa. Todos os fragmentos, exceto o último em um datagrama, devem ter um múltiplo de 8 bytes – a unidade de fragmento elementar. Como são fornecidos 13 bits, há um máximo de 8192 fragmentos por datagrama, suportando um comprimento máximo de pacote até o limite do campo Comprimento Total. Trabalhando juntos, os campos Identificação, MF e Offset campos são usados para implementar o processo de fragmentação do datagrama conforme descrito por Forouzan e Fegan.
O campo Offset – ou deslocamento (13 bits) – do fragmento informa aonde no pacote atual esse fragmento se encaixa. Todos os fragmentos, exceto o último em um datagrama, devem ter um múltiplo de 8 bytes – a unidade de fragmento elementar. Como são fornecidos 13 bits, há um máximo de 8192 fragmentos por datagrama, suportando um comprimento máximo de pacote até o limite do campo Comprimento Total. Trabalhando juntos, os campos Identificação, MF e Offset campos são usados para implementar o processo de fragmentação do datagrama (Forouzan e Fegan, 2003).
Passando para a terceira palavra do cabeçalho, o próximo byte é o TTL (Time To Live). Seu nome remete ao seu significado histórico e não à forma como é utilizado atualmente. A intenção do campo é capturar pacotes que andam por aí em laços de roteamento e os descartar em vez de deixá-los consumindo recursos indefinidamente. Originalmente, TTL foi definido como um número específico de segundos que o pacote poderia viver, e os roteadores ao longo do caminho diminuiriam esse campo até atingir 0. No entanto, como era raro um pacote permanecer por 1 segundo em um roteador, e nem todos os roteadores têm acesso a um relógio comum, os roteadores apenas diminuíram o TTL em 1 ao encaminhar o pacote. Portanto, tornou-se mais uma contagem de saltos do que um temporizador, o que ainda é perfeitamente uma boa maneira de capturar pacotes que estão presos em laços de roteamento. Uma sutileza está na configuração inicial deste campo pelo host de envio: se configurado com um valor muito alto, os pacotes podm circular bastante antes de serem descartados; por outro lado, uma configuração com valor muito baixo pode ocasionar que o pacote não chegue ao seu destino. O valor padrão atual é 64. O campo Protocolo (8 bits) é simplesmente uma chave que identifica o protocolo de nível superior para o qual esse pacote IP deve ser passado. Alguns dos valores que são definidos neste campo são 6 para o protocolo TCP e 17 para o protocolo UDP, além de muitos outros protocolos que podem estar acima do IP na pilha de protocolos. Na sequência, o campo Checksum – ou soma de verificação (16 bits) – é calculado considerando todo o cabeçalho IP como uma sequência de palavras de 16 bits, somando cada palavra por meio da aritmética de complemento a 1 e obtendo o complemento a 1 do resultado final. Assim, se algum bit do cabeçalho for corrompido em trânsito, a soma de verificação não conterá o valor correto após o recebimento do pacote. Como um cabeçalho corrompido pode conter um erro no endereço de destino – e, como resultado, pode ter sido mal entregue – faz sentido descartar qualquer pacote que falhe quanto à soma de verificação.
Para calcular o complemento a 1 de um número binário basta com que seus bits sejam invertidos (0 vira 1 e 1 vira 0). Nesse sentido, a soma por meio da aritmética de complemento a 1 é efetuada por meio de uma soma simples bit-a-bit de dois números considerando-os como positivos. Caso a soma resulte em um bit a mais que a presentação de ambos os números, basta ignorar esse bit excedente e incrementar o resultado final em uma unidade. Ex: 01010 + 11010 = 100100 (bit “1” excedente), logo o resultado final é 00100 + 1 = 00101.
Os dois últimos campos obrigatórios no cabeçalho são o Endereço de Origem e o Endereço de Destino, ambos de 32 bits. Este último é a chave para a entrega de datagramas: Cada pacote contém um endereço completo para o destino pretendido, para que decisões de encaminhamento possam ser tomadas em cada roteador. O endereço de origem é necessário para permitir que os destinatários decidam se desejam aceitar o pacote e para permitir que eles respondam. Importante ressaltar que o IP define seu próprio espaço global de endereçamento, independente de qualquer rede física sobre a qual ele passa. Essa é uma das chaves para que ele dê suporte à heterogeneidade das redes. Finalmente, podem haver várias outras opções no final do cabeçalho. A presença ou ausência de opções pode ser determinada examinando o campo de comprimento do cabeçalho (HL). Embora as opções sejam usadas raramente, uma implementação completa do protocolo IP deve ser capaz de lidar com todos eles.
Funcionamento do IPv4
O encaminhamento é o mecanismo básico pelo qual roteadores IP viabilizam o tráfego de datagramas em uma rede. Ele constitui o processo de pegar um pacote em uma entrada e enviá-lo para a saída apropriada, O roteamento, no entanto, é o processo de construção das tabelas que permitem determinar a saída correta de um pacote. Os fundamentos principais do processo de encaminhamento de datagramas IP são:
- Todo datagrama IP contém o endereço IP do host de destino.
- A parte da rede de um endereço IP identifica exclusivamente um único rede física que faz parte da Internet maior.
- Todos os hosts e roteadores que compartilham a mesma parte do endereço de rede estão conectados à mesma rede física e podem se comunicar enviando quadros pela rede.
- Toda rede física que faz parte da Internet possui pelo menos um roteador que, por definição, também está conectado a pelo menos uma outra rede física; este roteador pode trocar pacotes com hosts ou roteadores em qualquer rede.
O encaminhamento de datagramas IP podem, portanto, ser executados da seguinte maneira:
Um datagrama é enviado de um host de origem para um host de destino, possivelmente passando por vários roteadores ao longo do caminho. Qualquer nó, seja ele um host ou um roteador, primeiro tenta estabelecer se está conectado à mesma rede física que o host de destino. Para fazer isso, ele compara a parte da rede do endereço de destino com a parte da rede do endereço de cada uma de suas interfaces de rede. Normalmente, os hosts têm apenas uma interface, enquanto os roteadores teem, em geral duas ou mais interfaces em função de estarem conectados a duas ou mais redes. Se ocorrer uma correspondência, isso significa que o destino está na mesma rede física que a interface e o o pacote pode ser entregue diretamente nessa rede.
Se o nó não estiver conectado à mesma rede física que o nó de destino, ele precisará enviar o datagrama para um roteador. Em geral, cada nó pode escolher dentre vários roteadores e, portanto, precisa escolher o melhor, ou pelo menos um que tenha uma chance razoável de encaminhar o datagrama para mais próximo de seu destino. O roteador escolhido é conhecido como o roteador do próximo salto. O roteador encontra o próximo salto correto consultando sua tabela de encaminhamento. A tabela de encaminhamento é conceitualmente apenas uma lista de pares (Número de Rede, Próximo Salto). Normalmente, também há um roteador padrão usado se nenhum dos disponíveis nas entradas na tabela correspondem ao número de rede do destino. Para um host, pode ser aceitável ter um roteador padrão e nada mais – isso significa que todos os datagramas destinados a hosts que não estão na mesma rede física ao qual o host de envio está conectado será enviado através do roteador padrão.
Sub-redes e Endereçamento sem Classes
Sub-redes fornecem um primeiro passo para a redução do número total de números de rede que são atribuídos. A ideia básica é pegar um único número de rede IP e alocar os endereços IP com esse número de rede para várias redes físicas, que são chamadas de sub-redes. Para isso, alguns passos adicionais precisam ser tomados. Primeiramente, as sub-redes devem estar próximas umas das outras. Isso ocorre porque, sob a óptica de um ponto distante na Internet, todas as sub-redes parecerão como uma única rede, tendo apenas um número de rede entre eles. Isso significa que um roteador poderá selecionar apenas uma rota para alcançar qualquer uma das sub-redes. Logo, é melhor que todos estejam no mesmo caminho geral. Uma situação ideal para o uso de sub-redes é um campus grande ou uma organização que possui muitas redes físicas. De fora do campus, tudo o que cada host precisa saber para alcançar qualquer sub-rede interna é onde o campus se conecta com o restante da Internet. Isso geralmente ocorre em um único ponto, Portanto, uma única entrada na sua tabela de encaminhamento será suficiente. Mesmo se houver vários pontos a partir dos quais o campus se conecta ao restante da Internet, saber como chegar a um ponto na rede do campus ainda é uma bom ponto de partida.
O mecanismo pelo qual um único número de rede pode ser compartilhado entre várias redes envolve a configuração de todos os nós em cada sub-rede com uma máscara de sub-rede. Com endereços IP simples, todos os hosts na mesmo a rede devem ter o mesmo número de rede. A máscara de sub-rede permite portanto, a introdução de um número de sub-rede. Neste caso, todos os hosts de uma mesma rede física terão o mesmo número de sub-rede, o que significa que os hosts podem estar em redes físicas diferentes, mas compartilhar um único número de rede. Assim, o que uma sub-rede significa para um host é que agora ele está configurado com ambos endereços – um endereço IP e uma máscara de sub-rede para a sub-rede à qual ele está conectado. Como exemplo, na figura a seguir (adaptada de Peterson e Davie) o host H1 está configurado com um endereço de 128.96.34.15 e uma máscara de sub-rede 255.255.255.128. Importante observar que todos os hosts em uma determinada sub-rede são configurados com a mesma máscara de sub-rede; isto é, existe exatamente uma máscara de sub-rede por sub-rede. A execução de um AND bit-a-bit desses dois números define o número da sub-rede do host e de todos os outros hosts na mesma sub-rede. Neste caso, 128.96.34.15 AND 255.255.255.128 é igual a 128.96.34.0, portanto, esse é o número da sub-rede ao qual H1 está conectado.
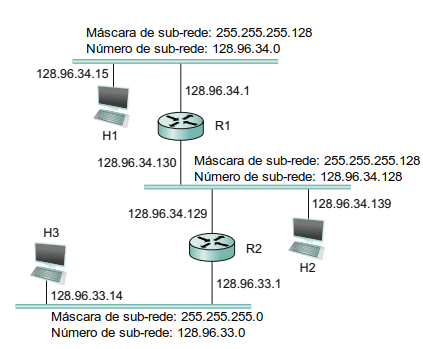
Ainda com base no exemplo da acima, quando um host deseja enviar um pacote para um determinado endereço IP, ele precisa primeiramente executar um AND bit a bit entre sua própria máscara de sub-rede e o endereço IP de destino. Se o resultado for igual ao número da sub-rede do host de envio, ele sabe que o host de destino está na mesma sub-rede e o pacote pode ser entregue diretamente pela sub-rede. Por outro lado, se os resultados não forem iguais, o pacote precisará ser enviado a um roteador para então ser subsequentemente encaminhado para outra sub-rede. No caso da Figure 3, se H1 estiver enviando para H2, então quando H1 executa o AND binário da sua máscara de sub-rede (255.255.255.128) com o endereço de H2 (128.96.34.139) ele obtém 128.96.34.128. O endereço IP obtido não corresponde ao número da sub-rede ao qual H1 está conectado (128.96.34.0). Logo, H1 sabe que H2 está em uma sub-rede diferente. Como o H1 não pode entregar o pacote ao H2 diretamente pela sub-rede, ele envia o pacote para o roteador padrão R1.
A tabela de encaminhamento de um roteador também precisa sofre uma alteração quando o conceito de sub-redes é introduzido. Conforme dito previamente, uma tabela de encaminhamento consiste em entradas no formato (Número de Rede, Próximo Salto). Porém, para oferecer suporte a sub-redes, a tabela agora deve conter entradas no formato (Número de Sub-rede, Máscara de Sub-rede, Próximo Salto). Assim, para encontrar a entrada correta na tabela, o roteador deve executar uma operação AND bit-a-bit do endereço de destino do pacote com a máscara de sub-rede para cada entrada por sua vez. Se o resultado corresponder ao número de sub-rede da entrada, esta é a entrada correta a ser usada e ele prossegue com o encaminhamento do pacote para o próximo salto ou roteador indicado. Na rede de exemplo da figura acima, o roteador R1 poderia ter entradas como mostrada na tabela a seguir.
| Número de Sub-rede | Máscara de Sub-rede | Próximo Salto |
| 128.96.34.0 | 255.255.255.128 | Interface 0 |
| 128.96.34.128 | 255.255.255.128 | Interface 1 |
| 128.96.33.0 | 255.255.255.0 | R2 |
Continuando com o exemplo de rede da última figura acima, quando H1 está enviando um datagrama para H2, R1 teria que efetuar o AND bit-a-bit do endereço de H2 (128.96.34.139) com a máscara de sub-rede da primeira entrada (255.255.255.128) e comparar o resultado (128.96.34.128) com o número da rede para essa entrada (128.96.34.0). Como os valores não são correspondentes, o roteador deve prosseguir para a próxima entrada. Desta vez, ocorre uma correspondência, então o R1 entrega o datagrama para H2 usando a interface 1, que é a interface conectada à mesma rede que H2.
Conclusão
Neste artigo, foi possível detalhar as diferenças de funcionamento entre uma rede de datagramas e comunicações orientadas a conexão ou circuitos virtuais.
O fato do protocolo IP ser baseado em uma comunicação cuja abordagem é sem conexão traz mais eficiência para o trânsito de datagramas, embora não ofereça garantia de entrega. Qualquer melhoria na qualidade de entrega de pacotes fica a cargo de protocolos da camada de transporte como o TCP. A flexibilidade do protocolo IP ficou evidente pelo detalhamento de todos os campos de seu cabeçalho, e a dinâmica da comunicação IP também foi apresentada, inclusive para redes que implementam o conceito de sub-redes.




1 Comentários
Parabéns! Postagem bem completa.